最近在做用户行为分析,我选择了用 Rmd 来做,好迁移,好修改,部署简单;其中一块结果我希望使用类似 GitHub Contributions Chart 的样式做展示。最终实现的效果差强人意,但是折腾的过程还是挺有意思的。
关于 GitHub Contributions Chart
这个图大概长这样:
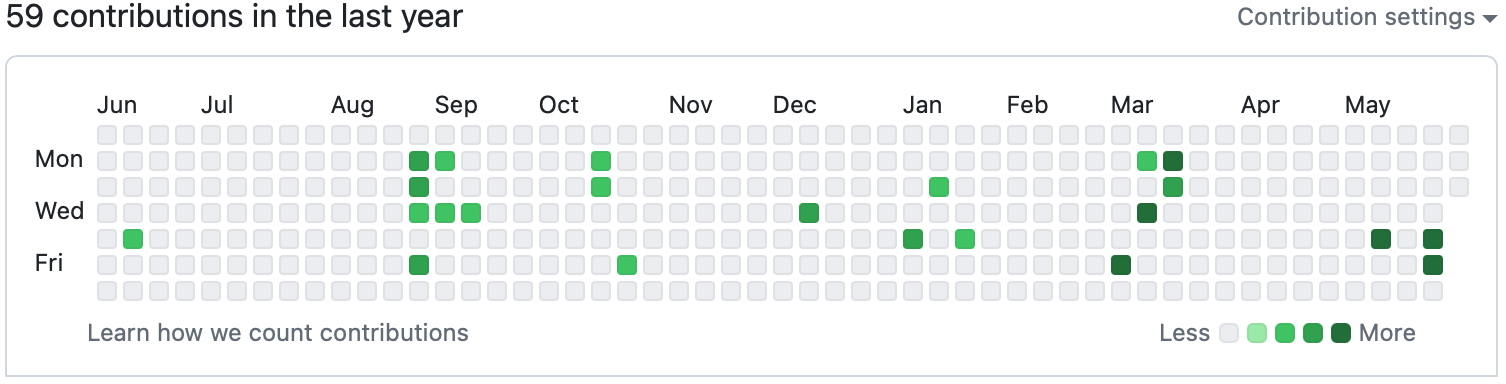
如果是 GitHub 上面的数据,可以使用 在线工具 实现;那如果我要展示的是本地数据呢?分析一下,这个图本质上是一个热图,我需要的数据就是一个两列表:
- 日期
- contributions
下面我生成一个示例数据,逐步分享一下我是怎么做数据处理并生成图片的;
数据处理
我的实际数据是形如"2024-03-26 14:40"格式,日期+时间;需要注意,传给我的日期数据已经是 POSIXct 类型了,如果你的数据是字符串类型,需要先处理成可认读的日期格式;我们先生成类似的数据结构:
data <- data.frame( datetime = as.POSIXct(c("2024-03-26 14:40", "2024-03-27 09:15", "2024-03-28 18:30", "2024-03-29 07:00", "2024-03-30 20:45", "2024-03-31 13:20", "2024-04-01 16:10")) )如果你的数据直接就是包含需要展示的 contributions 内容了,那么直接使用就可以了;我的数据不包括这部分内容,是每一行包含一个日期,这一行我期望视为一个 contribution, 这就需要 group_by 一下;
首先将日期转换为周数,星期,以及计算每个日期的 contributions; 需要用到 R 包 lubridate 来解析日期时间,R 包 dplyr 处理数据:
library(lubridate)
library(dplyr)
# 提取日期,星期等信息
data <- data %>%
mutate(
date = as.Date(submit_time),
week = format(submit_time, "%U"),
weekday = format(submit_time, "%A"),
month = format(submit_time, "%b")
)
# 按日期计算每日贡献次数
daily_contributions <- data %>%
group_by(date, weekday, month, week) %>%
summarise(contributions = n(), .groups = "drop") %>%
ungroup()
# 将 weekday 转换为因子,确保按周一到周日排序
daily_contributions$weekday <- factor(daily_contributions$weekday, levels = c("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"))
# 将 month 转换为因子,按月份顺序排序
daily_contributions$month <- factor(daily_contributions$month, levels = month.abb)
# 看看效果
head(daily_contributions)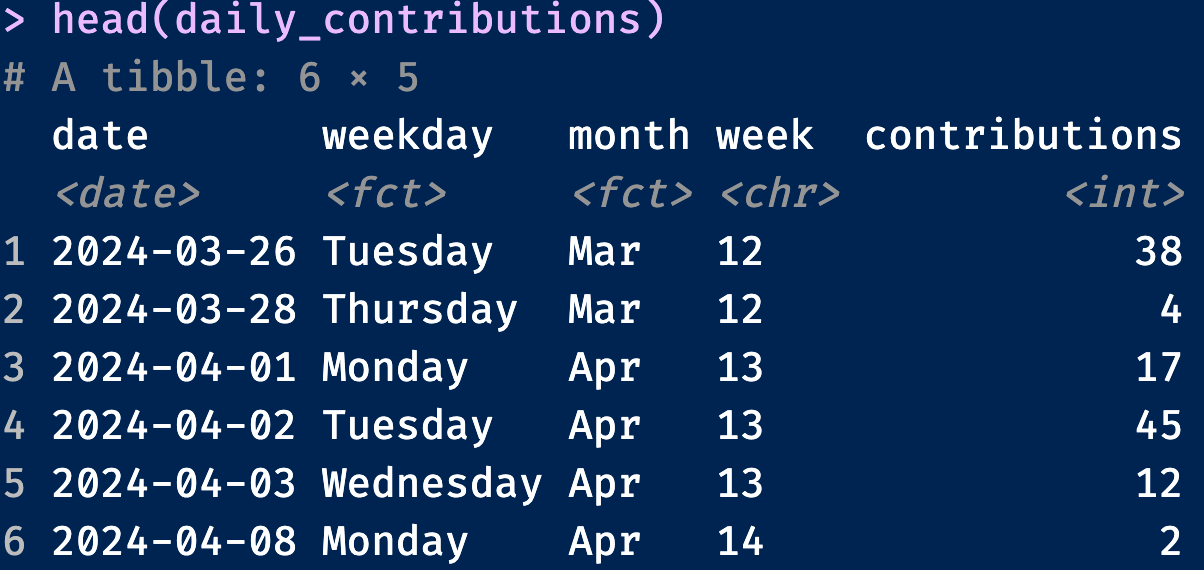
如果直接用这个数据作图会遇到以下几个问题:
- 假如数据中没有 Monday 的数据,最终展示图中就会完全没有 Monday 的图,这显然不是我们期望的;
- 实际数据可能不需要展示全部时间的内容,比如我们只分析进一个月的用户行为,我展示近 5 周的数据就完全足够了,但是流过来的数据可能是全部时间的,需要做一步筛选;
这里折腾了挺久,最终我的解决方案如下:
- 依据数据中最终日期,计算"五周前"的日期具体是哪一天,记为
start_time; - 过滤
daily_contributions中早于start_time的数据; - 生成
start_time到最终日期的表,记做all_data, contributions 全部填充为 0; - 去除
all_data中,daily_contributions已包含的日期; - 合并两个表格;
实际数据中应该不会出现"完全没有星期一"这种情况,但是以防万一还是处理一下吧。
# 过滤掉五周前的数据
last_date <- max(daily_contributions$date)
start_date <- last_date - weeks(5)
daily_contributions <- daily_contributions %>%
filter(date >= start_date)
# 生成五周内的全数据
all_dates <- seq(start_date, last_date, by = "day")
# 生成最近五周全部日期的数据框,并设置 contribution 为 0
all_data <- data.frame(
date = all_dates,
weekday = factor(weekdays(all_dates), levels = c("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday")),
month = factor(months(all_dates), levels = month.name),
week = format(all_dates, "%U"),
contributions = 0 )。
# 删除已有日期,保证以现有数据为准
existing_dates <- daily_contributions$date all_data <- all_data[!all_data$date %in% existing_dates, ]
# 合并现有数据和生成数据
combined_data <- bind_rows(daily_contributions, all_data)由于实际数据可能出现极端值,最好处理一下;我的数据情况比较适合归一化,或者直接 pmin () 一下也行;
# 归一化
max_contribution <- max(combined_data$contributions)
if(max_contribution != 0) {
combined_data$contributions <- combined_data$contributions / max_contribution
}作图
作图就比较简单了,ggplot2 就可以:
library(ggplot2)
ggplot(combined_data, aes(
x = week,
y = weekday,
fill = contributions
)) +
geom_tile(color = "white") +
scale_fill_gradient(low = "gray95", high = "darkgreen") +
labs(title = "GitHub Contributions Heatmap",
x = "Week",
y = "Day of the Week",
fill = "Contributions") +
theme_bw() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))效果展示:
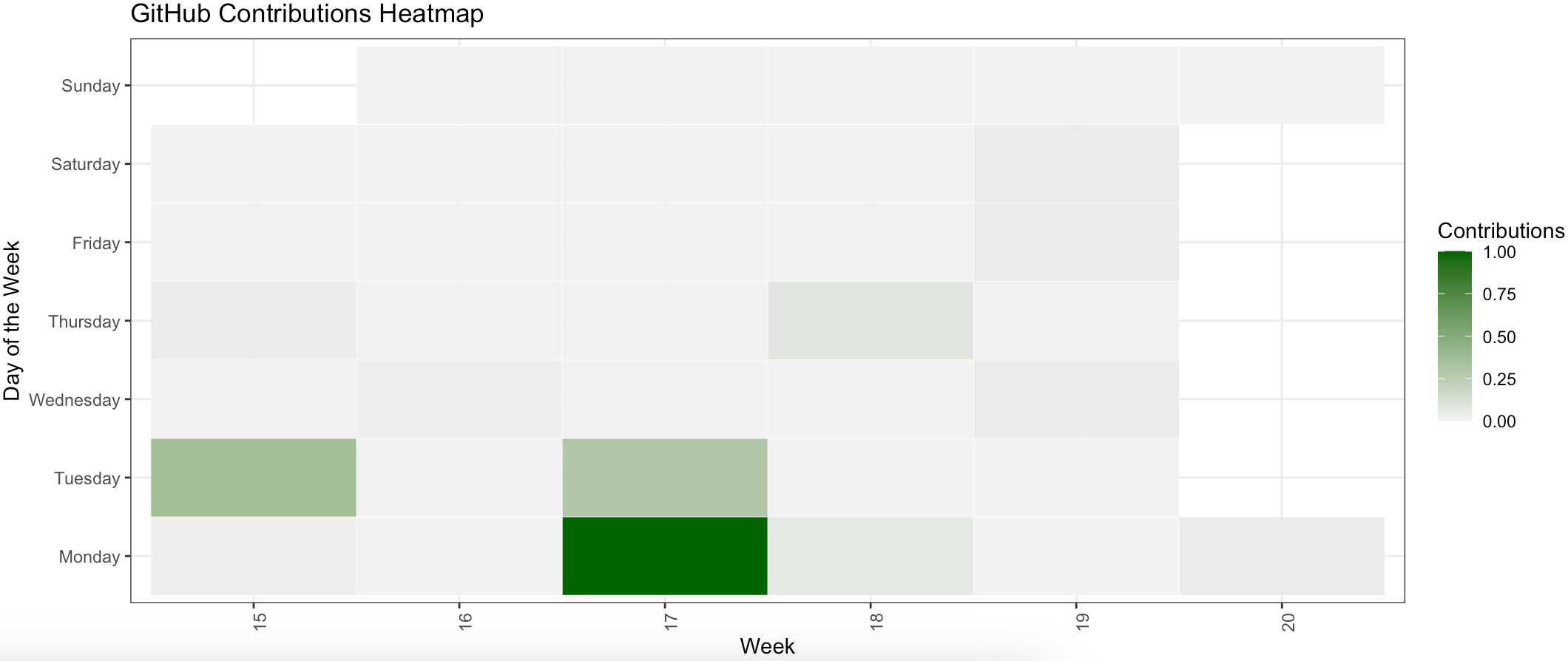
总结
美观性还是差一些,python 中的 matplotlab 似乎实现的效果好一点,但是我这限制了必需用 R 实现;能用倒是能用;
明明选了近五周数据,最终体现出来的是六周,估计是上面过滤数据中 start_date <- last_date - weeks(5) 这里有问题,要求严格的和可以以天为单位减,不严格就这么着吧。
实际上整体不太满意,感觉部分处理有点糙,比如合并一个空表格进来这种操作,应该可以更精巧一点。但是这里需要从交付思维出发,同事需要这部分结果,那我就应该尽快交付出去,让整个流程继续向下流转;毕竟"又不是不能用", 对吧。